
Arjhun S
@arjuns0206This article assumes that you know how basic RNNs work.
LSTM, or Long-Short-Term-Memory is an advancement on the Simple RNN. While RNNs struggle with maintaining long-term dependencies due to the vanishing gradient problem, LSTMs are designed to address this limitation by incorporating a more sophisticated memory mechanism.
LSTMs are a critical step in the evolution of sequence models, playing a foundational role in the development of transformers, which are now the backbone of modern models like GPT, BERT, and other state-of-the-art architectures.
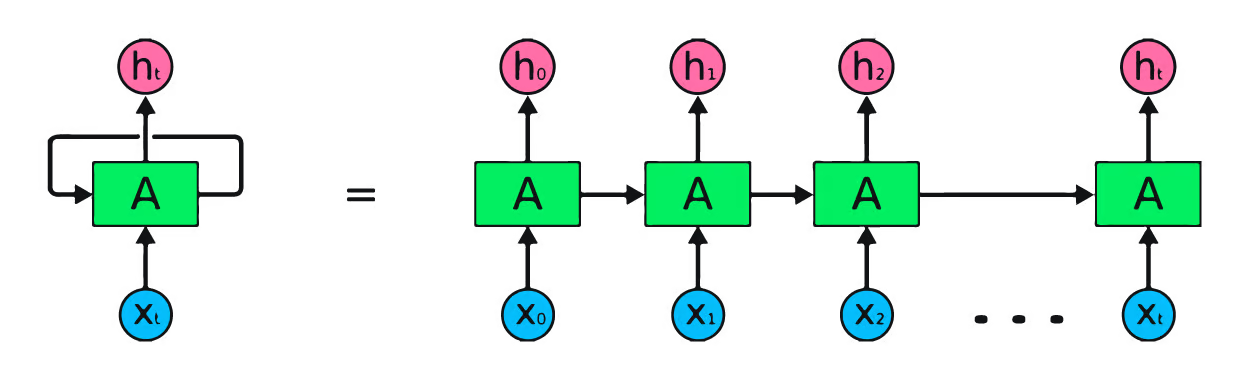
The main idea behind this network is to process sequential data, which means, the better the model can retain memory across time-steps, the better it can generate or predict similar sequences. Below is a simple visualisation of an RNN.
 datacamp.com
datacamp.com
The weights and biases of the same RNN cell is updated sequentially for each input Xt at time step t. This means that, when you have potentially long sequences, the model could forget inputs from initial time steps.
Moreover, simple RNNs are known to face vanishing/exploding gradients problem due to the same weights being constantly used for long sequences of data. More info here.
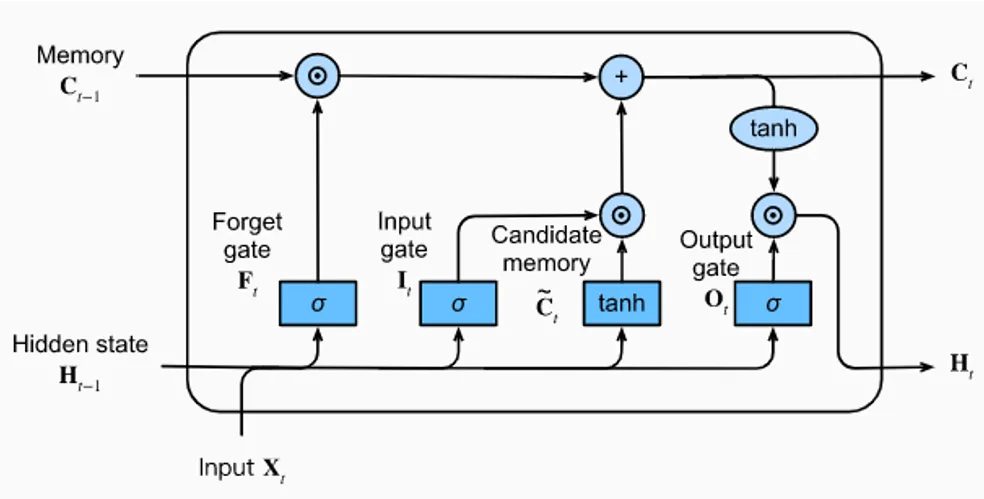
The LSTM model attempts to alleviate this issue by maintaining a long-term memory and short-term memory which is updated at every time-step. There are 3 gates in an LSTM. The forget, input and output gates, respectively.
 https://medium.com/@ottaviocalzone/an-intuitive-explanation-of-lstm-a035eb6ab42c
https://medium.com/@ottaviocalzone/an-intuitive-explanation-of-lstm-a035eb6ab42c
The Memory (Ct-1 ) refers to the long-term memory. And the hidden state ( Ht-1 ) refers to the short-term memory or the output from the previous time-step. This is called the short-term memory because this is analogous to the memory retained in a Simple RNN.
Now let’s understand what each of the gates do.
Forget gate
The forget gate is nothing but a linear fully connected NN, which uses 2 inputs, Xt and Ht-1 (short-term memory) to update the long-term memory. I know you’re wondering why this is called the forget gate.
It’s because this gate essentially decides how much of the existing long-term memory we’re going to retain.
Input gate
The input gate has 2 sections. One that calculates the candidate memory using the short-term memory from time t-1 and the input at time t,and another that learns how much of the candidate memory should be added to the long-term memory.
This is done by doing a element wise dot product, which decides whether or not certain memory is added to the long-term memory. Note that candidate memory uses the tanh activation, unlike the other gates which use the sigmoid function. This is because the long-term memories should be able to increase or decrease when we add the output from the input gates. Sigmoid output is always non-negative; values in the state would only increase. The output from tanh can be positive or negative, allowing for increases and decreases in the state.
Output gate
The output gate, has a singular network, which decides what short-term information should be used to predict the next output. This output is added to the long-term memory after tanh being applied to it (for the same reasons mentioned above).
This output becomes our new short-term memory as well as the output of the current time step t (Ht ).
Let’s go ahead an build an LSTM from scratch using just tensors and linear layers.
class LSTMCell(nn.Module):
def __init__(self, config):
super().__init__()
input_size = config.input_size # Input size (e.g., word embeddings)
hidden_size = config.hidden_size # Hidden state size
# One linear layer computes all 3 gates (1, 2, 1) at once
self.fc = nn.Linear(input_size + hidden_size, 4 * hidden_size)
def forward(self, x, stm, ltm):
"""
x -> Current input
stm -> Short-term memory (hidden state)
ltm -> Long-term memory (cell state)
"""
combined = torch.cat((x, stm), dim=-1) # Merge input & hidden state
gates = self.fc(combined) # Compute all gate values
# Split into four separate gates
forget_gate, input_gate, output_gate, cell_candidate = gates.chunk(4, dim=-1)
# Apply activation functions
forget_gate = torch.sigmoid(forget_gate) # Forget past memory
input_gate = torch.sigmoid(input_gate) # Decide new memory
output_gate = torch.sigmoid(output_gate) # Output from memory
cell_candidate = torch.tanh(cell_candidate) # Candidate for new memory
# Update long-term memory (LTM)
ltm = forget_gate * ltm + input_gate * cell_candidate
# Compute new short-term memory (STM)
stm = output_gate * torch.tanh(ltm)
return stm, ltmThe code is pretty self-explanatory. The single FC layer contains all the weights we need for all the gates. This makes things simpler because we have the same inputs for all the 3 gates. Note that the input gate needs 2 sets of weights.
The forward function calculates values for each gate, and in-turn uses them to update long and short-term memories. Make sure to reinitialise ltm and stm such that memories from one sequence does not affect other sequences in your data. It comes down to how many different sequences you have in your dataset.
I have not included the logic for how this cell would combine with an RNN or other training caveats. Maybe this could help.
I hope this articles helped you get a basic understanding of LSTMs along with how it could be coded out in PyTorch.
Cheers!